
さて、最近Facebookで承認したアプリや文学フリマの売り上げなど、あらゆるものに裏切られてきて、WordPressプラグイン開発という本来なら自分が得意なことにも裏切られました。
作っていたのはMeCabSweetという、形態素解析エンジンMeCabをWordPressから色々使えるようにしたやつですね。基本的な機能は以下の2つ。
- FullTextインデックスを利用した高速全文検索
- ユーザー辞書をメンテナンス
1個目はあれですね、ほら、よく検索機能とかで「本屋 東京」とかで検索したいとかいう要望あるじゃないですか。でも、「東京」はカテゴリーにしちゃったからなんかめんどくさいみたいなの。
そういうのを超高速に検索できるようにして、しかもgroongaとかじゃなくて、AmazonのRDSとか、設定をいじれないMySQLでも動くようになったら便利だなと思って作ったんですが、全然速度出なかったんですよねー。
なので、諦めました。
2個目の機能、ユーザー辞書をメンテナンスというのはわりかしうまくいきました。たとえば、破滅派という僕がやっている文芸サイトでは、「破滅派が大好きです」をわかちがきしたときに「破滅派」が「破滅」と「派」にわかれたら困るわけです。そこで、MeCabにある「ユーザー辞書」という機能を使って、「破滅派は固有名詞だよ」とMeCabに教えてあげるわけです。
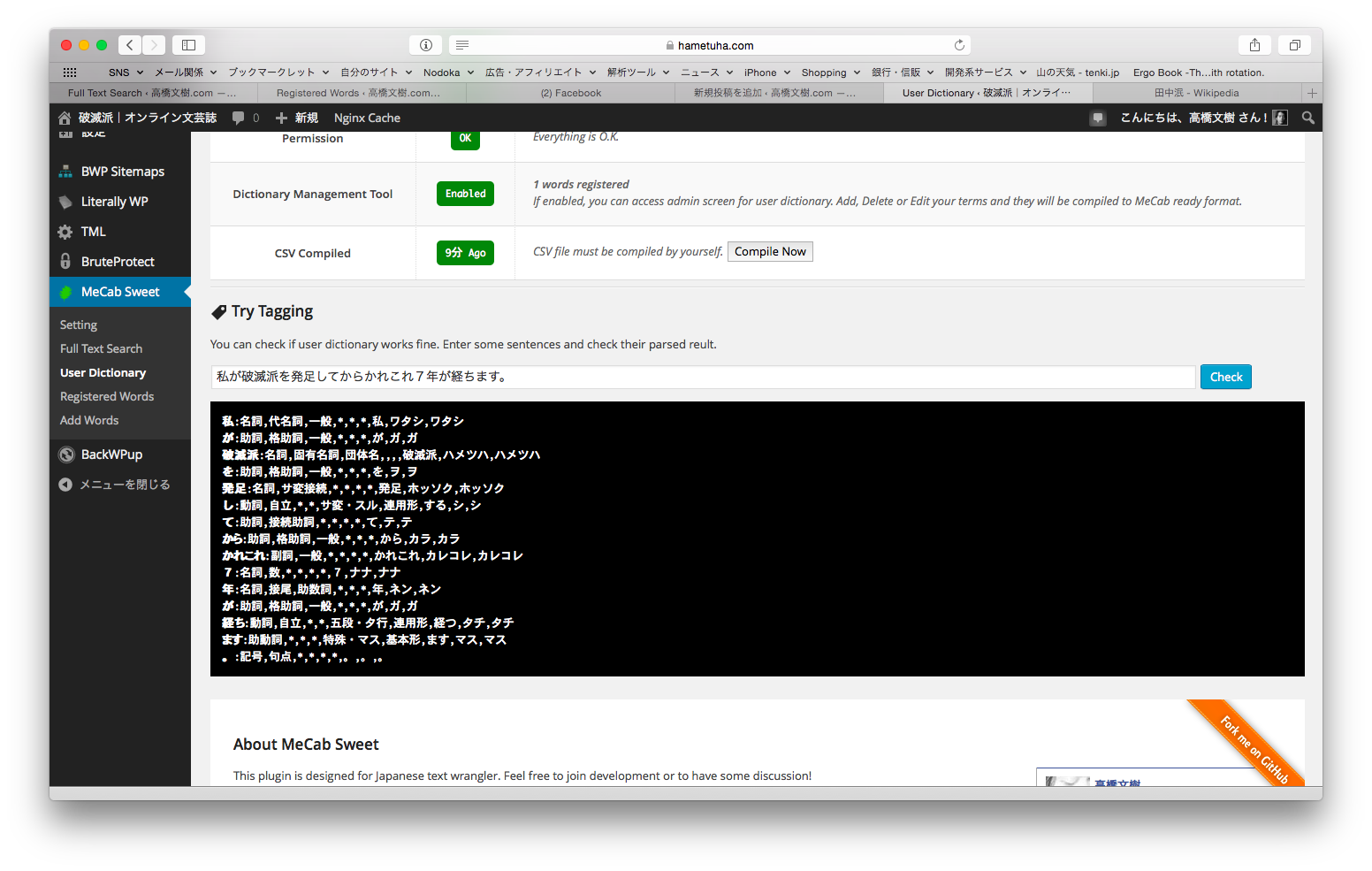
仕組みとしては、WordPressに登録した単語をCSVに解析し、それを辞書にコンパイルするという単純なものです。
このぐらいのプラグインすぐ作れるだろと思ってましたが、結構時間かかりましたね。しかも、中途半端なパフォーマンスだし。
WordPressのREST APIについても「公式プラグインがしょぼいから俺がOAuth2で実装しやるよプゲラ」とか思ってましたが、いやはやくじけそうです。
なんでMeCabを使うのか
さて、なんでWordPressからMeCabを使うのかというと、いま自然言語処理を色々やりたいなと思っているからなんですが、NLTKとかを使って計量する前にWordPressで色々加工しておいた方が楽なんじゃないかなーと思いまして。
Pythonも多少いじれるようにはなってきましたが、単語のチャンキングとか、辞書のメンテとかはWordPressでやった方が楽なような気がしています。
あと、ユーザー自身に辞書のメンテナンスをやってもらいたい(ex. 小説の登場人物名)というのもあり、トライしてみました。
ほんとはね、色々やりたいことはあるんですよ。登場人物の登場回数とか、表現の偏りを可視化したりとか。なにはともあれ形態素解析ができないとどうにもならんということで取り組んでみた次第です。
興味のある方はGithubのリポジトリを覗いてみてください。朝が来るまで日付は変わらないということで、俺ベントカレンダー1日目を終わりにします。まる。
コメントを投稿するにはログインしてください。